




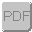
 Data Replication with SQL Remote
Data Replication with SQL Remote
PART 2. Replication Design for SQL Remote
CHAPTER 8. SQL Remote Design for Adaptive Server Enterprise
An UPDATE conflict occurs when the following sequence of events takes place:
User 1 updates a row at remote site 1.
User 2 updates the same row at remote site 2.
The update from User 1 is replicated to the consolidated database.
The update from User 2 is replicated to the consolidated database.
When the SQL Remote Message Agent replicates UPDATE statements, it does so as a separate UPDATE for each row. Also, the message contains the old row values for comparison. When the update from user 2 arrives at the consolidated database, the values in the row are not those recorded in the message.
By default, the UPDATE still proceeds, so that the User 2 update (the last to reach the consolidated database) becomes the value in the consolidated database, and is replicated to all other databases subscribed to that row. In general, the default method of conflict resolution is that the most recent operation (in this case that from User 2) succeeds, and no report is made of the conflict. The update from User 1 is lost.
SQL Remote also allows custom conflict resolution, using a stored procedure to resolve conflicts in a way that makes sense for the data being changed.
UPDATE conflicts do not apply to primary key updates. If the column being updated is a primary key, then when the update from User 2 arrives at the consolidated database, no row will be updated.
This section describes how you can build conflict resolution into your SQL Remote installation at the consolidated database.
 How SQL Remote handles conflicts
How SQL Remote handles conflictsSQL Remote replication messages include UPDATE statements as a set of single row updates, each including the values prior to updating.
An UPDATE conflict is detected by the database server as a failure of the values to match the rows in the database.
Conflicts are detected and resolved by the Message Agent, but only at a consolidated database. When an UPDATE conflict is detected in a message from a remote database, the Message Agent causes the database server to take two actions:
The UPDATE is applied.
Any conflict resolution procedures are called.
UPDATE statements are applied even if the VERIFY clause values do not match, whether or not there is a RESOLVE UPDATE trigger.
 The method of conflict resolution is different at an Adaptive Server Anywhere consolidated database. For more information, see How SQL Remote handles conflicts.
The method of conflict resolution is different at an Adaptive Server Anywhere consolidated database. For more information, see How SQL Remote handles conflicts.
Implementing conflict resolutionThis section describes what you need to do to implement custom conflict resolution in SQL Remote.
For each table on which you wish to resolve conflicts, you must create three database objects to handle the resolution:
An old value table To hold the values that were stored in the table when the conflicting message arrived.
A remote value table To hold the values stored in the table at the remote database when the conflicting update was applied, as determined from the message.
A stored procedure To carry out actions to resolve the conflict.
These objects need to exist only in the consolidated database, as that is where conflict resolution occurs. They should not be included in any publications.
When a table is marked for replication, using the sp_add_remote_table or sp_modify_remote_table stored procedure, optional parameters specify the names of the conflict resolution objects.
The sp_add_remote_table and sp_modify_remote_table procedures take one compulsory argument, which is the name of the table being marked for replication. It takes three additional arguments, which are the names of the objects used to resolve conflicts. For example, the syntax for sp_add_remote_table is:
exec sp_add_remote_table table_name
[ , resolve_procedure ]
[ , old_row_table ]
[ , remote_row_table ]
You must create each of the three objects resolve_procedure, old_row_table, and remote_row_table. These three are discussed in turn.
old_row_table This table must have the same column names and data types as the table table_name, but should not have any foreign keys. When a conflict occurs, a row is inserted into old_row_table containing the values of the row in table_name being updated before the UPDATE was applied. Once resolve_procedure has been run, the row is deleted.
As the Message Agent applies updates as a set of single-row updates, the table only ever contains a single row.
remote_row_table This table must have the same column names and data types as the table table_name, but should not have any foreign keys. When a conflict occurs, a row is inserted into remote_row_table containing the values of the row in table_name from the remote database before the UPDATE was applied. Once resolve_procedure has been run, the row is deleted.
As the Message Agent applies updates as a set of single-row updates, the table only ever contains a single row.
resolve_procedure This procedure carries out whatever actions are required to resolve a conflict, which may include altering the value in the row or reporting values into a separate table.
Once these objects are created, you must run the sp_add_remote_table or sp_modify_remote_table procedure to flag them as conflict resolution objects for a table.
At an Adaptive Server Enterprise database, conflict resolution will not work on a table with more than 128 columns while the VERIFY_ALL_COLUMNS option is set to ON. Even if VERIFY_ALL_COLUMNS is set to OFF, if an UPDATE statement updates more than 128 columns, conflict resolution will not work.
A first conflict resolution exampleIn this example, conflicts in the Customer table in the two-table example used in the tutorials are reported into a table for later review.
The two-table database is as follows:
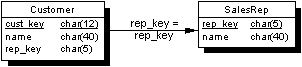
The conflict resolution will report conflicts on updates to the name column in the Customer table into a separate table named ConflictLog.
The conflict resolution tables are defined as follows:
CREATE TABLE OldCustomer( cust_key CHAR( 12 ) NOT NULL, name CHAR( 40 ) NOT NULL, rep_key CHAR( 5 ) NOT NULL, PRIMARY KEY ( cust_key ) ) CREATE TABLE RemoteCustomer( cust_key CHAR( 12 ) NOT NULL, name CHAR( 40 ) NOT NULL, rep_key CHAR( 5 ) NOT NULL, PRIMARY KEY ( cust_key ) )
Each of these tables has exactly the same columns and data types as the Customer table itself. The only difference in their definition is that they do not have a foreign key to the SalesRep table.
The conflict resolution procedure reports conflicts into a table named ConflictLog, which has the following definition:
CREATE TABLE ConflictLog ( conflict_key numeric(5, 0) identity not null, lost_name char(40) not null , won_name char(40) not null , primary key ( conflict_key ) )
The conflict resolution procedure is as follows:
CREATE PROCEDURE ResolveCustomer
AS
BEGIN
DECLARE @cust_key CHAR(12)
DECLARE @lost_name CHAR(40)
DECLARE @won_name CHAR(40)
// Get the name that was lost
// from OldCustomer
SELECT @lost_name=name,
@cust_key=cust_key
FROM OldCustomer
// Get the name that won
// from Customer
SELECT @won_name=name
FROM Customer
WHERE cust_key = @cust_key
INSERT INTO ConflictLog ( lost_name, won_name )
VALUES ( @lost_name, @won_name )
END
This resolution procedure does not use the RemoteCustomer table.
The stored procedure is the key to the conflict resolution. It works as follows:
Obtains the @lost_name value from the OldCustomer table, and also obtains a primary key value so that the real table can be accessed.
The @lost_name value is the value that was overridden by the conflict-causing UPDATE.
Obtains the @won_name value from the Customer table itself. This is the value that overrode @lost_name. The stored procedure runs after the update has taken place, which is why the value is present in the Customer table. This behavior is different from SQL Remote for Adaptive Server Enterprise, where conflict resolution is implemented in a BEFORE trigger.
Adds a row into the ConflictLog table containing the @lost_name and @won_name values.
After the procedure is run, the rows in the OldCustomer and RemoteCustomer tables are deleted by the Message Agent. In this simple example, the RemoteCustomer row was not used.
 To test the example:
To test the example:Create the tables and the procedure in the consolidated database, and add them as conflict resolution objects to the Customer table.
Insert and commit a change at the consolidated database. For example:
UPDATE Customer SET name = 'Sea Sports' WHERE cust_key='cust1' go COMMIT go
Insert and commit a different change to the same line at the remote database. For example:
UPDATE Customer SET name = 'C Sports' WHERE cust_key='cust1' go COMMIT go
Replicate the change from the remote to the consolidated database, by running the Message Agent at the remote database to send the message, and then at the consolidated database to receive and apply the message.
At the consolidated database, view the Customer table and the ConflictLog table. The Customer table contains the value from the remote database:
cust_key |
name |
rep_key |
|---|---|---|
cust1 |
C Sports |
rep1 |
The ConflictLog table has a single row, showing the conflict:
conflict_key |
lost_name |
won_name |
|---|---|---|
1 |
Sea Sports |
C Sports |
A second conflict resolution exampleThis example shows a slightly more elaborate example of resolving a conflict, based on the same situation as the previous example, discussed in A first conflict resolution example.
In this case, the conflict resolution has the following goals:
Disallow the update from a remote database. The previous example allowed the update.
Report the name of the remote user whose update failed, along with the lost and won names.
In this case, the ConflictLog table has an additional column to record the user ID of the remote user. The table is as follows:
CREATE TABLE ConflictLog ( conflict_key numeric(5, 0) identity not null, lost_name char(40) not null , won_name char(40) not null , remote_user char(40) not null , primary key ( conflict_key ) )
The stored procedure is more elaborate. As the update will be disallowed, rather than allowed, the lost_name value now refers to the value arriving in the message. It is first applied, but then the conflict resolution procedure replaces it with the value that was previously present.
The stored procedure uses data from the temporary table #remote. In order to create a procedure that references a temporary table you first need to create that temporary table. The statement is as follows:
CREATE TABLE #remote ( current_remote_user varchar(128), current_publisher varchar(128) )
This table is created in TEMPDB, and exists only for the current session. The Message Agent creates its own #remote table when it connects, and uses it when the procedure is executed.
CREATE PROCEDURE ResolveCustomer
AS
BEGIN
DECLARE @cust_key CHAR(12)
DECLARE @lost_name CHAR(40)
DECLARE @won_name CHAR(40)
DECLARE @remote_user varchar(128)
-- Get the name that was present before
-- the message was applied, from OldCustomer
-- This will "win" in the enx
SELECT @won_name=name,
@cust_key=cust_key
FROM OldCustomer
-- Get the name that was applied by the
-- Message Agent from Customer. This will
-- "lose" in the end
SELECT @lost_name=name
FROM Customer
WHERE cust_key = @cust_key
-- Get the remote user value from #remote
SELECT @remote_user = current_remote_user
FROM #remote
-- Report the problem
INSERT INTO ConflictLog ( lost_name,
won_name, remote_user )
VALUES ( @lost_name, @won_name, @remote_user )
-- Disallow the update from the Message Agent
-- by resetting the row in the Customer table
UPDATE Customer
SET name = @won_name
WHERE cust_key = @cust_key
END
There are several points of note here:
The user ID of the remote user is stored by the Message Agent in the current_remote_user column of the temporary table #remote.
The UPDATE from the Message Agent is applied before the procedure runs, so the procedure has to explicitly replace the values. This is different from the case in SQL Remote for Adaptive Server Anywhere, where conflict resolution is carried out by BEFORE triggers.
To test the example:Create the tables and the procedure in the consolidated database, and add them as conflict resolution objects to the Customer table.
Insert and commit a change at the consolidated database. For example:
UPDATE Customer SET name = 'Consolidated Sports' WHERE cust_key='cust1' go COMMIT go
Insert and commit a different change to the same line at the remote database. For example:
UPDATE Customer SET name = 'Field Sports' WHERE cust_key='cust1' go COMMIT go
Replicate the change from the remote to the consolidated database, by running the Message Agent at the remote database to send the message, and then at the consolidated database to receive and apply the message.
At the consolidated database, view the Customer table and the ConflictLog table. The Customer table contains the value from the consolidated database:
cust_key |
name |
rep_key |
|---|---|---|
cust1 |
Consolidated Sports |
rep1 |
The ConflictLog table has a single row, showing the conflict and recording the value entered at the remote database:
conflict_key |
lost_name |
won_name |
remote_user |
|---|---|---|---|
1 |
Field Sports |
Consolidated Sports |
field_user |
Run the Message Agent again at the remote database. This receives the corrected update from the consolidated database, so that the name of the customer is set to Consolidated Sports here as well.
Designing to avoid referential integrity errorsThe tables in a relational database are related through foreign key references. The referential integrity constraints applied as a consequence of these references ensure that the database remains consistent. If you wish to replicate only a part of a database, there are potential problems with the referential integrity of the replicated database.
Referential integrity errors stop replication |
By paying attention to referential integrity issues while designing publications you can avoid these problems. This section describes some of the more common integrity problems and suggests ways to avoid them.
Consider the following SalesRepData publication:
exec sp_add_remote_table 'SalesRep' exec sp_create_publication 'SalesRepData' exec sp_add_article 'SalesRepData', 'SalesRep' go
If the SalesRep table had a foreign key to another table (say, Employee) that was not included in the publication, inserts or updates to SalesRep would fail to replicate unless the remote database had the foreign key reference removed.
If you use the extraction utility to create the remote databases, the foreign key reference is automatically excluded from the remote database, and this problem is avoided. However, there is no constraint in the database to prevent an invalid value from being inserted into the rep_id column of the SalesRep table, and if this happens the INSERT will fail at the consolidated database. To avoid this problem, you could include the Employee table (or at least its primary key) in the publication.