




 User's Guide
User's Guide
PART 1. Working with Databases
CHAPTER 5. Summarizing, Grouping, and Sorting Query Results
Understanding which queries are valid and which are not can be difficult when the query involves a GROUP BY clause. This section describes a way to think about queries with GROUP BY so that you may understand the results and the validity of queries better.
 How queries with GROUP BY are executed
How queries with GROUP BY are executedConsider a single-table query of the following form:
SELECT select-list
FROM table
WHERE search-condition
GROUP BY group-by-expression
HAVING search-condition
This query can be thought of as being executed in the following manner:
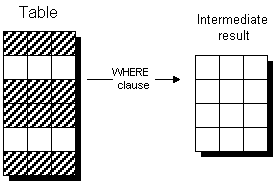
Apply the WHERE clause This generates an intermediate result that contains only some of the rows of the table.
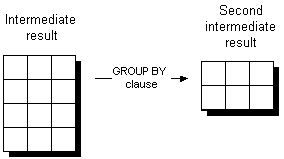
Partition the result into groups This action generates an intermediate result with one row for each group as dictated by the GROUP BY clause. Each row contains the group-by-expression for each group and the operands of any aggregate functions in the select-list.
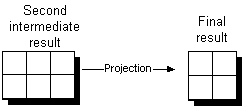
Apply the HAVING clause Any rows that do not meet the criteria of the HAVING clause are removed at this point.
Project out the results to display This action takes from the second intermediate result only those columns that need to be displayed in the result set of the query.
This process makes requirements on queries with a GROUP BY clause:
The WHERE clause is evaluated first. Therefore, any aggregate functions are evaluated only over those rows that satisfy the WHERE clause.
The final result set is built from the second intermediate result, which holds the partitioned rows. The second intermediate result holds rows corresponding to the group-by-expression. Therefore, if a column appears in both the select-list and the group-by-expression, it must do so in the same form. No function evaluation can be carried out during the projection step.
A column can be included in the group-by-expression but not in the select-list. It is projected out in the result.
GROUP BY with multiple columnsYou can list more than one column in the GROUP BY clause in order to nest groups—that is, you can group a table by any combination of columns.
 To list the average price of products, grouped first by name and then by size:
To list the average price of products, grouped first by name and then by size:Enter the following command:
SELECT name, size, AVG(unit_price) FROM product GROUP BY name, size
name |
size |
AVG(unit_price) |
|---|---|---|
Tee Shirt |
Small |
9.000 |
Tee Shirt |
Medium |
14.000 |
Tee Shirt |
One size fits all |
14.000 |
Baseball Cap |
One size fits all |
9.500 |
Visor |
One size fits all |
7.000 |
Sweatshirt |
Large |
24.000 |
Shorts |
Medium |
15.000 |
A Sybase extension to the SQL/92 standard that is supported by both Adaptive Server Enterprise and Adaptive Server Anywhere is to add columns to the GROUP BY clause that are not in the select list. For example, the following query lists the number of contacts in each city:
SELECT state, count(id) FROM contact GROUP BY state, city
WHERE clause and GROUP BYYou can use a WHERE clause in a statement with GROUP BY. The WHERE clause is evaluated before the GROUP BY clause. Rows that do not satisfy the conditions in the WHERE clause are eliminated before any grouping is done. Here is an example:
SELECT name, AVG(unit_price) FROM product WHERE id > 400 GROUP BY name
Only the rows with id values of more than 400 are included in the groups that are used to produce the query results.
An exampleThe following query illustrates the use of WHERE, GROUP BY, and HAVING clauses in one query:
SELECT name, SUM(quantity) FROM product WHERE name LIKE '%shirt%' GROUP BY name HAVING SUM(quantity) > 100
name |
SUM(quantity) |
|---|---|
Tee Shirt |
157 |
In this example:
The WHERE clause includes only rows that have a name including the word shirt (Tee Shirt, Sweatshirt).
The GROUP BY clause collects the rows with a common name.
The SUM aggregate calculates the total number of products available for each group.
The HAVING clause excludes from the final results the groups whose inventory totals do not exceed 100.