Data Integrity and Consistency
Integrity and Consistency Features
Sybase pioneered server-enforced data integrity that removes the responsibility of enforcing integrity from individual client applications. Using Transact-SQL extensions, application developers can create organization-wide business rules and integrity controls, which SQL Server stores centrally and applies to client applications network-wide.
Transact-SQL supplies all the tools you need to create integrity constraints. They include the create table command and SQL Server datatypes, rules, defaults, triggers, and stored procedures (described in Chapter , ``Transact-SQL and Utilities''). At the most basic level, SQL Server verifies that the value a user enters conforms to the datatype requirements associated with the column. To define more specific domains, you can create rules and check constraints, which limit the values users can insert into a column by checking the value against a condition you specify.
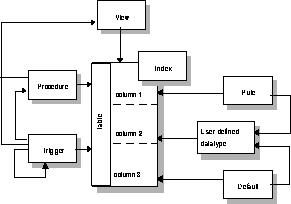
Figure 8-1 shows the relationship between SQL Server database objects in their roles as integrity enforcement mechanisms. The sections below describe these roles and interactions.
Summary of Integrity Constraints
Table 8-1 summarizes the types of data integrity constraints and the Transact-SQL options available for enforcing them.
Unique Constraints
Unique constraints govern the degree to which entries in a column must be unique with respect to null values. Transact-SQL provides two mechanisms for implementing unique constraints using the create table command. Both conform to ISO/ANSI SQL 1989 standards for create table.
Referential Integrity Constraints
Referential integrity constraints guarantee that each foreign key in a detail table has a valid primary key in the master table. The following two mechanisms enforce referential constraints:

Rules and Check Constraints
A rule or check constraint limits the values allowed in a column. Every time a value is entered through an insert or update command, SQL Server checks it against the most recent rule or constraint on the column. Data entered prior to the creation and binding of a rule or the addition of a constraint is not checked. You can use the alter table command to drop or change a check constraint.
Check constraints are included in the table definition, as this example illustrates.
create table publishers ( pub_id char(4)
check (pub_id in ("1389", "0736", "0877"))
pub_name char(40),
etc.)
Rules are created with the create rule command, and then bound to a column or user-defined datatype with the sp_bindrule system procedure. The rule that the next example creates enforces the same domain constraints as the declarative constraint created by the last example.
create rule pub_idrule
as @pub_id in ("1389", "0736", "0877")
sp_bindrule pub_idrule, "publishers.pub_id"
You can bind the same rule to many columns. For example, if many tables use an employee_id column, you can create one rule and bind it to all of the employee_id columns in the database. An even simpler approach is to create a user-defined datatype (say, employee_id_type) and bind the rule to the datatype. Whenever you create a table with an employee_id_type column, the rule is bound to that table column. Triggers can enforce more complex types of domain constraints as described later in this chapter.
Defaults
Defaults define a default value that SQL Server inserts if a value is not supplied (an error results if you supply an invalid value). You can create defaults using create table's create default and default options. create default defines a default value and links it to a single column, to a number of columns, or to all the columns of a specified user-defined datatype. For example, you might create the default value "undefined" for SQL Server to insert a user does not specify a value. You can drop or change a default at any time.
User-Defined Messages for Constraints
The Sybase system procedures sp_addmessage and sp_bindmessage provide a way to create custom messages for the application that you can bind to check constraints and referential integrity constraints. The following example creates a constraint called positive_bal that ensures that the account balance is greater than zero.
create table account
( acct_number int
branch int
balance money
constraint positive_bal check (balance > 0))
sp_addmessage 30100, NULL, "You can not perform transactions that result in a negative account balance."
sp_bindmsg positive_bal, 30100Any update operations that violate this constraint yield the following message:
You cannot perform transactions that result in a negative account balance.
if update (column_name) begin SQL Statements end if update (column_name) and update (column_name) begin SQL Statements endThe trigger "fires" immediately after a data modification statement completes. SQL Server treats the trigger and the statement which fires it as a single transaction that can be rolled back from within the trigger. If a severe error is detected, the entire transaction can be rolled back. Transact-SQL also provides a rollback trigger command to roll back only data modifications performed in the trigger.
Here are some of the reasons that triggers are so useful:
Conditional Triggers
The triggers described so far consider each data modification statement as a whole. If one row of a four-row insert was unacceptable, the whole insert was unacceptable and the transaction was rolled back.
Nested and Recursive Triggers
Triggers can nest¯in other words, a trigger can call other triggers. A trigger that changes a table on which there is another trigger can fire that second trigger. This in turn can fire a third trigger, and so forth.
Database Consistency Checking
To check the logical and physical consistency of a database, you can use the Transact-SQL dbcc command. dbcc calls the Database Consistency Checker, which is actually a set of utilities that are used when a severe system error has been generated or used by the System Administrator as a periodic check.