Resource Management Features
If you don't tell SQL Server where to put databases, tables, and indexes, and allocate enough space to each of them, then SQL Server uses default locations and space allocations for them. These defaults work to bring a system up and get it running, however, in almost every case, you'll achieve optimum performance if you customize SQL Server for your site. After an application stabilizes and you determine its data-handling requirements, you can fine tuning your system's physical resources by using the techniques outlined in this chapter. This chapter describes the following topics:
Recovery
Although SQL Server supports non-stop recovery in a number of ways, disk mirroring is probably the most important method for achieving seamless failover in the event of a hard disk crash. Mirroring the database devices that contain the data and indexes¯not just the device containing the transaction log¯is required for recovery without downtime. The section below, ``Disk Mirroring'' discusses mirroring in more detail.
Performance
There are some very effective ways to optimize system performance via physical placement of tables, indexes, and logs. If a table spans several physical disks, SQL Server can use partitions to distribute the table across those disks dramatically improving insert performance. Other ways to manage disks to improve performance include:
Commands for Managing Physical Resources
Table 9-2 lists the commands most commonly used to manage the allocation of physical resources.
Database Devices
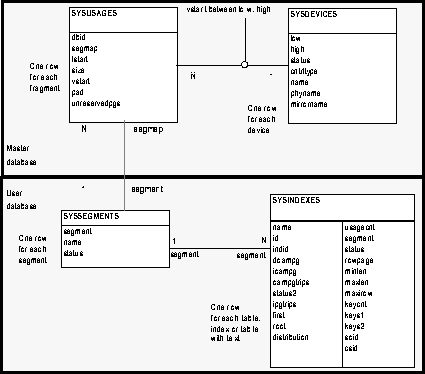
A database device is dedicated to the storage of the objects that make up databases. The term "device" does not necessarily refer to a distinct physical device. It can refer to any region of a disk or a file in the file system that is used to store databases and database objects. Figure 9-2 shows a database with its log on one device, and other objects on another. This separation is important for reasons described in ``Assigning Databases to Database Devices''.
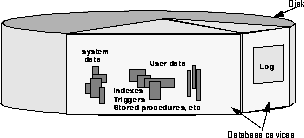
Initializing Database Devices
Each database device must be prepared and made known to SQL Server before it can be used for database storage. This process is called initialization. After a database device is initialized, it can be:
Designating Default Devices
To create a pool of default database devices to be used by all SQL Server users for creating databases, you use the sp_diskdefault command initializing devices with disk init. The sp_diskdefault command marks these devices as default devices. Whenever users create or alter databases without specifying a database device, new disk space is allocated from the pool of default disk space.
Assigning Databases to Database Devices
The commands create database and alter database allocate storage space to databases. In most organizations, only the System Administrator issues these commands to prevent inadvertent or unauthorized use of storage space. create database creates the new database on the devices you specify, and alter database adds space to an existing database.
Assigning the Transaction Log to a Database Device
The log on extension to create database places the transaction log (the syslogs table) on a separate database device. There are several reasons for placing the logs on a separate logical database device. For example:
Deciding What to Mirror
When deciding to mirror a device, you must weigh such factors as the costs of system downtime, possible reduction or improvements in performance, and the cost of storage media. Such determinations will help you decide what to mirror¯just the transaction logs, all devices on a server, or selected devices.
Disk Mirroring Using Minimal Disk Space
Figure 9-3 illustrates the "minimum guaranteed configuration" for database recovery in case of hardware failure. The master device and a mirror of the user database transaction log are stored in separate partitions on one physical disk. The other disk stores the user database and its transaction log in two separate partitions.

Disk Mirroring for Non-Stop Recovery
Figure 9-4 represents another mirror configuration. In this case, the master device, user databases, and the transaction log are all stored on different partitions of the same physical device and are all mirrored to different partitions on a second physical device.
The configuration in Figure 9-4 provides non-stop recovery from hardware failure. Working copies of the master and user databases and log on the primary disk are all being mirrored, and failure of either disk will not interrupt SQL Server users.

Disk Mirroring for High Performance and Non-Stop Recovery
Figure 9-5 illustrates another configuration with a high level of redundancy. In this configuration, all three database devices are mirrored, but the configuration uses four disks instead of two. This configuration speeds performance during write transactions because the database transaction log is stored on a different device from the user databases, and the system can access both with less disk head travel.

These three illustrations show different solutions to weighing the cost and performance trade-offs:
Creating and Using Segments
Segments are named subsets of the database devices available to a particular SQL Server database. Conceptually, a segment is a label that points to one or more database devices. Segment names can be used in create table and create index commands to place the table and index objects on specific database devices. The use of segments can increase SQL Server performance, and can give the System Administrator or Database Owner increased control over placement and space usage of specific database objects. For example:
When you first create a database, SQL Server creates three segments in the database:
Getting Information About Storage
To find the name(s) of the database device(s) on which a particular database resides, use the system procedure sp_helpdb with the database name. For example:
sp_helpdb styledb
name db_size owner dbid created status ----- ----------- ------ ------ ------------ -------------------- style 12.0 MB sa 5 Nov 20, 1993 select into/bulkcopy device_fragments size usage free kbytes ---------------- ------ -------------- ----------- userdb_dev 8.0 Mb data only 2320 userdb_dev 2.0 Mb data only 352 log_dev 2.0 Mb log only 992To get a summary of the amount of storage space used by a database, execute the system procedure sp_spaceused:
sp_spaceused
database_name database_size -------------- --------------- styledb 12.0 MB reserved data index_size unused ------------ ------------ ------------ --------- 6100 KB 1992 KB 3210 KB 898 KB
Some tasks that thresholds and threshold-activated procedures can perform are:
Figure 9-6 shows a database segment with space remaining before the threshold. When user activity causes the space available in the database to decrease to the point where the threshold is reached, the threshold manager executes the stored procedure that is linked to that threshold.

The Last-Chance Threshold on the Log Segment
When you create a database so that its log is stored on a separate segment, SQL Server automatically creates a "last-chance threshold" on the log segment. The last-chance threshold protects the transaction log from the possibility that there will be no space on which to store the backup log records. The last-chance threshold guarantees that there will always be room to perform the log dump.
Figure 9-7 shows a last-chance threshold and a user-defined threshold on a transaction log segment. When the log fills to the user-defined threshold, SQL Server executes the stored procedure associated with that threshold and dumps the transaction log. The lower part of Figure 9-7 shows the space reclaimed after the dump completes.

Using Thresholds
Table lists the system procedures that manage thresholds on SQL Server.
When the threshold manager executes a procedure it passes these four arguments to the procedure:
Enhancing Performance Using Segments
In a large multidatabase and/or multidrive SQL Server environment, the allocation of space to databases and the placement of database objects on physical devices can enhance system performance. For greatest efficiency, a System Administrator can allocate space so that no heavily used database needs to share a physical disk with another database.
Table Partitioning
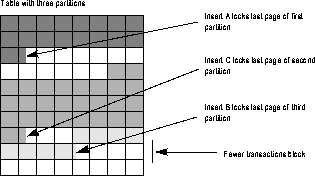
Distributing a heavily used table over several devices dramatically improves insert performance by reducing the chances for concurrent inserts to block. SQL Server 11 now lets you distribute (or partition) tables across disks. Partitioning improves system performance by increasing the rate at which data passes to cache by facilitating parallel loading. Instead of passing only one stream of data to one disk, the system can simultaneously pass several streams to several disks for the same table.
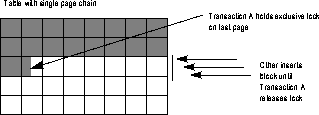
By default, SQL Server stores a heap table's data in one doubly linked chain of database pages. For example, an unpartitioned table that has no clustered index stores all data in a single "heap" of pages. When a transaction inserts a row into the table, it holds an exclusive page lock on the last page of the page chain while inserting the row. As multiple transactions attempt to insert rows into the same table at the same time, performance can suffer. Because only one transaction at a time can obtain an exclusive lock on the last page, other concurrent insert transactions block, as shown in Figure 9-8.
When a transaction inserts data into a partitioned table, SQL Server randomly assigns the transaction to one of the table's partitions. Concurrent inserts are less likely to block, since multiple last pages are available for inserts, as shown in Figure 9-9.