[Top] [Prev] [Next]
Chapter 1
Sybase System 11 Strategy
Overview
System 11 is a set of components that provides enterprise solutions for a wide range of database applications including data warehousing, on-line transaction processing (OLTP), decision support systems (DSS), and mass deployment. It works equally well over a variety of platforms from laptops to high-end clustered multiprocessing systems. The Sybase client/server family of products gives database system developers the flexibility to create solutions for an enormous range of distributed computing applications and to integrate almost any variety of hardware platforms and operating systems.
This chapter is an overview of the Sybase approach to distributed computing solutions and provides the technological context within which SQL Server fits. The discussion is based on the following topics:
Sybase Meets Today's Market Requirements
Sybase recognizes that the models governing enterprise computing are changing rapidly. Decentralization, transition, and increasing demands for efficiency are now the norm. Rather than try to elude these new paradigms, companies must incorporate them in a productive way to achieve success and stay ahead of the competition. These paradigms effect business in the following ways:
Organizations need the infrastructure that can help them to be the pace setters¯or they fall hopelessly behind. They need tools that ease the difficulty of constant change and the burden placed on employees as a result of streamlining measures.
A Family of High-Performance Products
Sybase recognizes the need for an infrastructure that can support the enterprise. For the next several years we'll be living in a multi-paradigm world: mainframes, client/server, and the Internet. Organizations will need to extend their legacy systems and develop applications for client/server and the Internet.
Sybase has developed a clear vision about technology needs now and for the future. This vision has produced a highly flexible product offering with customizable options for the three major classes of distributed applications: OLTP, data warehousing, and mass deployment. Organizations implement these applications using the three technology layers¯database, middleware, and tools¯as follows:
- At the database layer, Sybase offers a family of servers to implement fast, scalable data warehouses, OLTP, and mass deployment applications.
- At the middleware layer, Sybase provides server and interoperability products for data replication, enterprise messaging, and interoperability in any heterogeneous computing environment.
- At the tools layer, Sybase helps you develop and manage your system with administration and monitoring products, tuning, application development and debugging tools, and hundreds of Sybase Open Solutions Partner third-party applications.
Figure 1-1 summarizes Sybase's product strategy. It represents adaptive and complete system solutions. The architecture is adaptive because you can customize the components to meet your organization's distributed computing needs at every layer. The architecture is complete because Sybase products are fully integrated and optimized to work together. Also, because the products in each cell of the matrix are independent, you can use Sybase products with third-party products. For example, you can use a Sybase database with third-party middleware and tools, or you can use Sybase middleware and tools with third-party database engines.
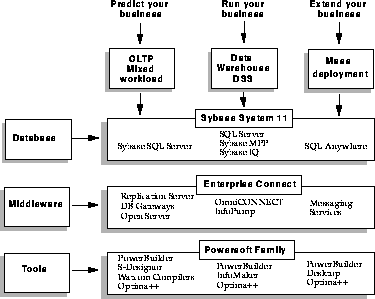
The following sections provide a quick overview of some of the Sybase products that can support your organization.
Database Layer
Sybase's databases for the enterprise include the following projects:
Middleware Layer
Some of Sybase's most popular middleware products are:
Tools Layer
Sybase tools include:
Mainframe Computing
Mainframe computing was the popular computing model before the client/server model became the widespread standard. In mainframe computing, the mainframe performs all processing and uses a "dumb" terminal (one with no processing power of its own) as a display unit. For example, retrieving and displaying employee information on a terminal requires the following steps:
- 1. Display a form on the terminal into which a user can enter an employee ID.
- 2. Accept the employee ID information.
- 3. Validate the format of the information.
- 4. Check the availability of the employee information.
- 5. Get the employee information from the database.
- 6. Format the data for display on the users terminal.
- 7. Display the employee information on the terminal.
We can categorize these tasks as those related to data presentation (steps 1, 6, and 7), those related to data validation (steps 2 and 3), and those related to data access (steps 4 and 5). The mainframe performs all of the steps because the terminal has no processing capability.
In the mainframe processing model, the server is heavily loaded because it performs all of the processing for every client. In the client/server model, however, clients can perform some portion of the application processing, such as data presentation and some data validation. This off-loading of some tasks to clients with processing power improves performance because the server has more time for processing requests.
Client/Server Computing in the Database Environment
In just the last few years, the client/server model has gone from being the "new trend" in distributed (networked) computing to the "traditional model" for implementing distributed computing. It divides processing into client applications and server applications that cooperate to accomplish tasks for the integrated application.
An Overview of Client/Server Concepts
Client applications make requests for service. Server applications receive requests and respond by returning data or other information to client applications, or by taking some action.
Figure 1-2 depicts a common client/server interaction. In this example, the client application makes a request and delivers it to the server. The server application receives the request and processes it. The server then takes action and/or returns a result to the client. The client receives the result (if a result was returned) and uses it to continue the task it was performing.
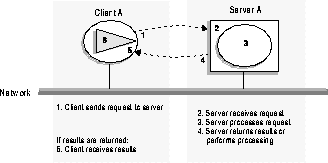
Sometimes a server can itself become a client to another server. Say Client A makes the request "print file chapter.doc". Server A retrieves chapter.doc from the file system and becomes a client to the printer server. Server A remains a client until the print job is done. If the printer server could not print chapter.doc, then Server A might return an error message to Client A to let it know that its request could not be granted.
Benefits of Client/Server Computing
Here are a few of the many advantages that client/server computing offers over the computing models that came before it:
Client/Server Nodes and Implementation
Client and server applications can reside on the same computer, or node; however, in a distributed computing environment, they usually reside on different nodes. Nodes are distinguished as client nodes and server nodes depending on their role.
Client nodes tend to be generalized. Computers that run client applications may include many types of clients, such as a directory client, a file client, and a print client. There are often many nodes running the same client applications so that a single server node, such as a print server, serves several client nodes. Although a single server node can accommodate more than one server application, system designers often implement server applications on dedicated server nodes because servers tend to be more specialized and require more processing and system resources than clients.
A server application is typically a continuous process (for example, a daemon in UNIX) while a client application is most often a standard application program. During the course of its normal processing, a client application calls API routines to send the requests to a server. When the client has finished its work, it stops execution. As a dedicated process, the server runs continuously: it waits for requests, detects them, processes them, returns the results, and then waits for the next request.
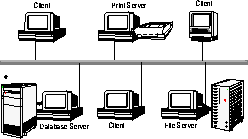
Figure 1-3 shows a typical relationship between client and server nodes on a network. Each client accesses all servers: database server, file server, and print server. The print server might be a client to the file server and the file server could be a client to the database server.
Relative Roles of Clients and Servers
The terms "client" and "server" characterize relative roles rather than absolute roles. For example, in executing a print request, the print server becomes a client if it has to ask a file server to send it a copy of the file it is going to print.
Architecture is fully functional when it allows clients to act as servers and servers to act as clients when necessary. For example, Sybase implements this capability with the Open Client and Open Server products. Sybase applications that have both client and server functionality incorporate both Open Client and Open Server libraries.
Figure 1-4 shows an example in which an application acts as both a client and a server. As a server, it responds to requests from and returns results to the Open Client application. As a client, it makes requests of the SQL Server and processes the results of those requests.

Sybase Client/Server Database Environment
In the Sybase client/server database environment, SQL Server runs all of the actual database management system¯it does all the processing associated with database access. The database server carries out the tasks initiated by client requests directed to the database. It is built on a multithreaded architecture and ensures data integrity, concurrency control, and the ability to recover from failures. The database server also maintains the data dictionary which defines the structure and contents of the database. The database client performs all the processing not associated with database access.
In the Sybase environment, "the database server" is SQL Server and "the database client" is any client software that can interact with SQL Server. The Sybase interactive SQL utility, ISQL, for example, is a client application that you use with SQL Server to execute ad hoc SQL queries. Files can be used as both the input source and the output destination. In general, the database client contains application-specific functionality and the processing related to interactions with the user's terminal such as typing characters to the screen, displaying cursor motions, and mapping the keystrokes.
It is more common for users to work with a program's GUI than for them to interact directly with the program. These GUIs are often forms into which the user enters information. For example, when a patient checks into a hospital, the intake nurse types registration information into a form managed by the client application. The client might perform input checking to make sure that the data entered is consistent with the type of information it should be. For example, it might check that the date entered for "Date of Birth" is a real date. The client then takes the information the user typed in and uses it retrieve or modify data via the server.
Configurations that Leverage Your Investment
Now that we've described what we mean by "client/server" computing, we can revisit the matrix shown in Figure 1-1. The Sybase product family provides a wide range of options and configurations with which to create any number of solutions for enterprises with distributed database requirements. The most common client/server configurations are based on the two-tier and three-tier models. The tiers use solutions from the database, middleware, and tools layers shown in Figure 1-1.
The Two-Tier Model
In a two-tier configuration, client applications connect directly to server applications and submit requests using Open Server applications or remote procedure calls (RPCs). RPCs allow users to open a connection to a single SQL Server, and that SQL Server can then access data from many other servers. A SQL Server application programmer can write custom event handlers to process client requests.
The first tier in a two-tier configuration consists of presentation and application logic. Examples of applications at this layer are:
The second tier in a two-tier configuration offers direct service management and handles connections. It can include database servers and general purpose servers such as e-mail and print servers. Examples of these applications are:
Figure 1-5 shows SQL Server and Open Server applications in a two-tier configuration.

The Three-Tier Model
When developers design and implement software using a component model, they create self-contained software blocks or components, each with a specific function. A component can be replaced by another that has the same specifications without rewriting or changing surrounding components. This component model for software design also results in the ability to reuse components.
Three-tier architecture, based on the component model, is a popular design solution for large or complex server applications that run under some type of middleware, such as a transaction processing monitor or an object-oriented environment. The three-tier architecture allows the flexibility and freedom to replace components without affecting the rest of the system.
Sybase is the only database company that makes it easy to implement an independent application in the middle tier of a three-tier software architecture. Figure 1-6 illustrates the three-tier topology using Sybase products.
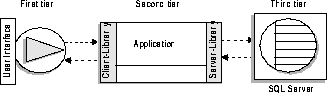
The functionality of each tier is as follows:
- The first tier supports presentation services on the client system. Minimally, it helps windowing systems display and manipulate data. This tier might also validate user input. This tier consists of Sybase products from the "tools" layer, such as PowerBuilder or Optima++.
- The second tier (or middle tier) can enforce business rules and referential integrity across all components of the third tier, supports global distributed transaction management, and supports service mapping similar to a gateway application. This tier is implemented as an intermediate server. It consists of Sybase products from the "middleware" layer, such as OmniCONNECT or Open Server.
- The third tier is a back-end server that handles data integrity and local transaction branches. It has local responsibility for controlled resources, which are often database systems. This tier consists of Sybase products from the "database" layer, such as SQL Server, Sybase MPP, Sybase IQ, and SQL Anywhere.
Three-tier architecture gives the application complete independence with respect to both the front-end tool and the back-end datastore and makes it easy to extend database functionality. Many MIS developers find the three-tier construct essential.
In environments that do not support a three-tier topology, developers must integrate business rules either in the front-end tool or the back-end datastore. Business rules can be integrated with the back-end datastore by programming them in stored procedures or a trigger, a special kind of stored procedure that automatically executes whenever data is inserted, updated, or deleted in the columns with which the trigger is associated. Programming business rules in triggers results in dependence on the datastore, so if business rules change, the database might need to be reoptimized. Chapter 8, "Data Integrity and Consistency" discusses triggers in more detail. Three-tier architecture gives you the capability to develop applications that are independent of the physical database design.
Enterprise-wide Client/Server Infrastructure
Typically, companies build client/server computing incrementally, starting with a departmental implementation and expanding the model to an enterprise-wide scale over time. The goal might be to make all applications work within the client/server model, or it might be to bring new applications on-line with cheaper or more modern technology, while avoiding the expense of converting legacy systems. Either way, the problem is one of infrastructure. What infrastructure can you standardize on to make the client/server model successful in the overall enterprise?
One of the essential considerations in choosing a client/server infrastructure to support the enterprise is how well the infrastructure can integrate existing applications and data sources. If some applications or data reside on mainframe computers, selecting an infrastructure can be challenging because it means choosing new technology that does not require reworking existing systems. Sybase Open Server Server-Library runs on the mainframe and works conveniently as a tool for integrating the mainframe into the client/server model.
It is possible to put together an enterprise-wide client/server infrastructure with similar components by mixing and matching from various vendors. For example, a company can acquire the peer-to-peer middleware pipe, a UNIX TP monitor, a database, various ODBC drivers, a set of system management tools, and gateways to the different data sources, all from different vendors. By the time the enterprise-wide client/server infrastructure is set up, the company will be working with six to ten vendors. The IS staff will have to learn eight or nine different technologies that were not designed and tested as an integrated unit, and there will undoubtedly be cross-vendor support issues. It is easier to be able to work with a single vendor and acquire a suite of products built on a common architectural framework. Sybase offers this alternative.
A Way to Integrate the Mainframe
The client/server solutions that many vendors provide assume that companies will downsize from mainframes to minicomputers, workstations, and personal computers. This approach makes sense in many cases; however, there are many other companies for which mainframe applications continue to meet needs well. These companies would rather find a way to extend mainframe applications and provide access to legacy data within a client/server environment than spend time and money converting all mainframe applications and migrating data to the smaller computer systems. The sentiment is, "why fix what isn't broken?"
Sybase offers enormous benefits by helping to build a client/server infrastructure that accommodates data and applications from a range of different sources. Many customers have adapted their mainframe applications using Sybase Open Server and OmniCONNECT to integrate legacy applications and data source into the client/server environment.
Support for On-line Transaction Processing
On-line transaction processing (OLTP) is characterized by a large number of users that need fast on-line access to small result sets. OLTP typically involves accessing and updating data in just a few tables. For example, a manager for a large toolstore chain wants to look up all the outstanding invoices for customer "L. Rico". Figure 1-7 shows that this query involves a simple join between the purchase and customer tables that returns three records.

Before Sybase introduced SQL Server in 1987, there were no strong relational OLTP engines supporting client/server architecture. Now, businesses use database OLTP applications extensively. Examples of these types of applications are:
Decision Support and Data Warehousing
In contrast to OLTP, it is common for decision support system (DSS) queries to access entire tables or large portions of tables, involve joins between many tables, and return summaries of large result sets. Decision support queries generally answer specific "what?" and "which¯?" questions. For example, "What were the most common New York departure times for female business travellers between the ages of 35 and 45 on Fridays during the last seven weeks?" It is usually acceptable for a query to take several minutes or even several hours to complete because it is part of a routine market research plan.
In data warehousing, data may come from different sources and be converted to a format that the database server can use to make queries. Data warehousing is a special branch of decision support¯the results of data warehouse queries are used to help make crucial business decisions. The user expects faster results than with a normal DSS query. Typical users of the data warehouse include managers, strategic marketers, and merchandisers looking for information to help them understand and predict market trends. Warehouse queries can answer questions such as:
Often, users need to make several adjustments to a query before it gives them the most valuable information. A user typically constructs ad hoc queries, then follows up by issuing further queries based on the information received.
Data Replication
If a large number of remote users and remote applications directly access a data warehouse for ad hoc queries, customized batch reports, and transaction processing, the network can get bogged down. Users and applications wait unacceptable lengths of time to get results.
For example, during peak banking hours, many tellers simultaneously use forms on their terminals to enter queries. This can generate a large amount of network traffic which translates to slow data access for the teller and bank patron if they are at a branch in a region of the country different from that of the database at headquarters.
Data replication is now one of the most common alternatives to direct access for distributed data to remote sites. It allows users direct access to data locally, eliminating the problems associated with remote access.
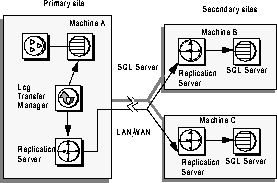
Replication Server
Replication Server lets you distribute data at remote sites. Replication Server transmits data from the primary database server (where data originates) to secondary sites (replicate database servers) on the users' local area network (LAN). Replication Server handles data transmission and ensures that each local server has an up-to-date copy of the data.
This approach is a solution for the problems associated with the direct access method described above. Using Replication Server is fast because it copies all the data to the local server, so users can access the data over the local network. Replication Server is also efficient, because it uses the store-and-forward technique to replicate modified data.
Replication Server puts no additional load on SQL Server, so even with large amounts of data, replication does not affect SQL Server performance. Oracle and Microsoft both use the DBMS to perform replication, which means large amounts of data will drag down performance for those systems. Figure 1-8 illustrates how Replication Server works:
SQL Remote
SQL Remote provides asynchronous replication with SQL Anywhere. For users who only occasionally connect, particularly for laptop users, Replication Server used with SQL Anywhere's SQL Remote capability provides two-way replication between SQL Anywhere and databases using the underlying mail system (MAPI, for example). Users log into the mail system to transmit and receive database changes, which is done through a publish-and-subscribe paradigm. Although it is not real-time replication as Replication Server provides, it complements the Replication Server environment.
MPP: Massively Parallel Processing
Processing for queries that involve massive amounts of data can be accelerated by dividing the work between several processors rather than letting a single processor to do all the work. This is called parallel processing, and it can greatly enhance performance for tasks such as sorts, aggregates, report generation, list management, and data maintenance. Parallel processing helps keep performance consistent as you add processors to handle increasing amounts of data, users, or both. Massively parallel processing (MPP) is parallel processing on a large scale.
Sybase MPP Server
Sybase MPP (previously known as Navigation Server), on MPP systems and clustered SMP, distributes processing by linking multiple SQL Servers into what appears to users to be a single large database server (Sybase MPP). The many machines work in parallel to accommodate a much larger database than is possible with any individual database server. All applications and users in the MPP environment communicate with the MPP Server instead of with individual SQL Servers performing the work. MPP Server breaks up the queries, manages processing on the multiple SQL Servers, and consolidates results while providing a consistent interface to users.
The SQL Server machines can be uniprocessor machines or symmetric multiprocessing machines (SMP) to achieve even greater performance gains. Figure 1-9 shows an example in which a service provider for marketing firms stores a national telephone directory database on an MPP system with three SMP machines.
The names are stored in alphabetical order such that the three SMP machines each contain one-third of the database: one contains last names starting with letters A to I, one for J to R, and one for S to Z.
If a customer wants to send marketing mail to all the people who live in the zip code 94114 area, Sybase MPP Server manages the processing so the work is divided among the SMP machines. The SMP machines work simultaneously to deliver all the addressing information for records in the database with a zip code equal to 94114, and the results are available in one third of the time.

Sybase IQ
Sybase IQ is another Sybase product that facilitates decision support in a data warehouse. Other database environments look up data in the database using an indexing method based on columns. The index stores the column identifier and a pointer to the data being indexed. This method occupies more space and takes longer than Sybase IQ's bitwise indexing scheme, a new technology introduced with Sybase IQ. Bitwise indexing is much more efficient than traditional indexing schemes for data sets that have small range of values (low cardinality) in a large number of rows, such as five million rows that accept the values "male" or "female."
Sybase IQ's index technology compresses data so that it uses as little as 40 percent as much disk space as uncompressed data uses. Compressing data also reduces the number of times that the server fetches data from disk, which is another big performance advantage because disk access is more time consuming than any other operation.
Sybase IQ's advanced indexing capability is the only offering of its kind in the industry, providing very fast query response times. Other RDBMS companies that offer parallel queries cannot handle complex analysis because they do not store intermediate result sets into temporary tables for continued drill-down. SQL Server with the MPP and IQ options covers the full range of warehousing and DSS applications with a consistent API set and a unified administration model.
Mass Deployment
Mass deployment is a Sybase term that describes applications that run both as independent (or standalone) databases on small systems and as connected nodes in a distributed computing environment.
SQL Anywhere is a PC-based full-function SQL database management system. It supports mobile options, such as remote networks, mobile computers, and other nomadic devices.
This "anywhere" concept for sharing data extends the data replication model. SQL Anywhere uses a new replication feature that permits two-way, message-based (email-like) replication of data between nodes¯for example, between the central database and a laptop in the field. When you log into the mail system, you can transfer and receive database changes. You can also develop applications on SQL Anywhere and later implement them on larger SQL Server systems without modifications.
Database APIs and Connectivity
The Open Client and Open Server APIs, based on ISO's Remote Database Access (RDA) Protocol, fulfill unique software requirements by allowing you to integrate your choice of third-party tools and services into the Sybase environment.
OmniCONNECT provides platform independence by allowing connections between a wide range of relational and non-relational databases so query results appear to come from a single source. For example, it can perform cross-platform table joins between SQL Server, VSAM, and Oracle.
Open Client
Open Client architecture supports non-Sybase APIs on top of its Client-Library API. Open Client Client-Library is a versatile interface for tools and applications that lets them access SQL Server data, other Sybase servers, and (when used with Open Server) non-Sybase data and services.
Client Library is an extension of an earlier Sybase client API, Sybase DB-Library. It incorporates cursors, ANSI SQL syntax, and the initiation of multiple actions on a single connection.
Open Client architecture makes it easy to integrate your non-Sybase applications and tools without the need for porting. For example, you can continue to use the SQL Access Group Call Level Interface or Microsoft's Open Data Connectivity (ODBC) API without modifying them first.
Open Server
Sybase is the only software company that opens the door to the client/server communication path on the server side. Many companies offer the developer a client-side API, but Sybase's Open Server uniquely offers a server-side API. The implication is that you can develop a custom server for any application or data source.
Sybase offers Open Server as an integrated component in its distributed client/server product line, which you can use to access any client tool or application. Figure 1-10 illustrates the concept.

Open Server In Enterprise-wide Computing
Open Server's ability to be any kind of server in any kind of client/server topology is an extremely valuable capability. In addition to its ability to solve an enormous variety of server application needs, Open Server can be the key component in making enterprise-wide client/server implementation possible.
Most Open Server applications are based on the following five configurations:
 Standalone Server¯A two-tier topology in which a client connects directly to a standalone Open Server application.
Standalone Server¯A two-tier topology in which a client connects directly to a standalone Open Server application.
 Gateway Server¯A three-tier topology in which Open Server acts as a translator between an Open Client application and a foreign data source.
Gateway Server¯A three-tier topology in which Open Server acts as a translator between an Open Client application and a foreign data source.
 Application Server¯A three-tier topology in which the Open Server application resides in a middle tier, independent of the client component and the data server.
Application Server¯A three-tier topology in which the Open Server application resides in a middle tier, independent of the client component and the data server.
 Auxiliary Server¯A three-tier topology in which Open Server extends the functionality of the primary server from the back end.
Auxiliary Server¯A three-tier topology in which Open Server extends the functionality of the primary server from the back end.
 Pass-through Server¯A three-tier topology in which Open Server transparently relays client requests and database responses.
Pass-through Server¯A three-tier topology in which Open Server transparently relays client requests and database responses.
With the Gateway Server and the Application Server configurations, Open Server can connect (transparently to the client) to a SQL Server, another data source, or many data sources.
Example: A Pass-Through Server
Pass-through (or transparent) is a three-tier configuration in which servers reside between the client application and the server that contains the data-store. The pass-through server relays client requests and database responses invisibly. Figure 1-11 shows the pass-through server configuration.

Examples of pass-through server configuration are:
Open Server is a Key Architectural Component
Sybase is the only major database vendor that offers a full complement of products for implementing and maintaining enterprise-wide client/server solutions. Sybase uses its own architecture to build new products quickly to meet market needs. Rather than reinventing or rebuilding the underlying communications infrastructure every time it builds a new product, Sybase uses its published Open Server and Open Client APIs in the same way that Sybase customers do. For example, Replication Server, OmniCONNECT, Gateway, Sybase MPP, Backup Server, Audit Server, and SQL Server Monitor are Sybase System 11 products built on an Open Server foundation.
OmniCONNECT
OmniCONNECT is a middleware solution that provides a uniform view of enterprise data to a client application. This view is defined in terms SQL Server, allowing client applications that were designed to interact with a SQL Server to interact unmodified with OmniCONNECT.
OmniCONNECT's key features are:
Using these basic capabilities, with OmniCONNECT you can join tables between two or more SQL Server systems and between two or more heterogeneous databases such as DB2, Oracle, and Sybase. You can also coordinate transactions between two or more servers. Transferring data from one server to another is as easy as using either a "select into" or a "insertselect" syntax. Finally, stored procedures let you extend business functions consistently across multiple databases.
Integration with DCE Services
Sybase is actively involved in the ongoing development of distributed computing environment (DCE) tools, services, and software. As a member of the Open Software Foundation (OSF), Sybase has worked with other industry providers to represent the needs of database vendors and to define requirements in this emerging market. Sybase provides support for DCE directory (naming) and security services and is committed to supporting a variety of distributed service solutions, encompassing not only DCE, but others such as Novell NetWare, Banyan StreetTalk, and Microsoft Windows NT. Because Sybase supports open computing and believes that DCE may be critical to some customers and of less interest to others, we provide complete, robust support for DCE as an option without requiring any customer to adopt this approach.
Many industry observers expect DCE to be pervasive in the market and used for large production applications after the next few years. Sybase is supporting DCE and other distributed services in a flexible manner and is poised for the future when the mass market begins wholesale adoption of these services.
[Top] [Prev] [Next] [Bottom]