Overview
SQL Server 11's multithreaded architecture is designed for high performance in both uniprocessor and multiprocessor systems. Performance and scalability were built into SQL Server from the outset by a design team that had previously developed three other relational database systems. Each module of the original database architecture was assigned a performance specification before coding began and was subsequently tested against the specification. SQL Server 11 is the result of this design approach and is one of the most advanced architectures available for relational database environments.
SQL Server's Process Model
SQL Server can manage a full load of thousands of client connections and multiple simultaneous client requests without over-burdening the operating system, because it is a multithreaded, single process server. That is, no matter how many users access SQL Server, it consumes only a single operating system process for each CPU and each connection consumes only about 65K of memory.
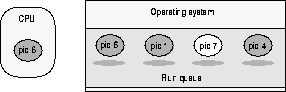
In systems supported by a single CPU, SQL Server runs as a single process sharing CPU time with other processes as scheduled by the operating system. Figure 2-1 shows a run queue for single CPU architecture in which the process with process identifier (PID) 8 is running on the CPU and PID 6, 7, 1, and 4 are waiting their turn in the run queue for CPU time. PID 7 in the figure is a SQL Server process; the others can be any operating system process.
Client Implementation
SQL Server clients are programs that open connections to SQL Server. Some examples are ISQL, Open Client Client-Library, and Optima++. A single client can open multiple connections to SQL Server, which launches a new client task (thread) for every new connection. SQL Server uses a dedicated stack to keep track of each client task's state during processing and ensures that only one thread at a time accesses a common, modifiable resource such as memory by using spinlocks. A spinlock is a special type of resource lock that helps synchronize access to code and memory areas that need to be accessed as though the environment were only single-threaded.
The Advantage of Threads Over Processes
Threads are subprocesses, or "lightweight processes" so called because they use only a small fraction of the operating system resources that a process uses. Multiple processes executing concurrently require more memory and CPU time than multiple threads of execution do. They also require operating system resources to switch context (time-share) from one process to the next.
Figure 2-2 illustrates the concept of context switching between three threads over time. In the figure, the large arrows pointing down represent the client task threads. They are receiving CPU time when they are solid (near the arrow head). They are in the run queue waiting for processing when they are broken lines. The small arrows represent context switching between each client task.
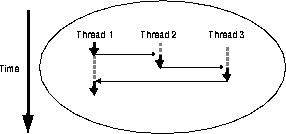
Figure 2-3 illustrates the difference in system resources required by client connections implemented as processes and client connections implemented as threads. Threads exist and operate within a single instance of the executing program process and its address space in shared memory.

Symmetric Multiprocessing
Virtual Server Architecture (VSA) extends the performance benefits of Sybase's multithreaded kernel architecture and SQL Server engines to multiprocessor systems. Sybase designed this VSA architecture for SQL Server version 4.8 to make efficient use of hardware and operating system resources.
Sybase SMP is intended for machines with the following features:
Scheduling Engines to CPUs
Figure 2-4 represents SQL Server engines as the non-shaded ovals waiting their turns in the run queue for processing time on one of three CPUs. It shows two SQL Server engines, PID 3 and PID 8, being processed simultaneously. If there was only a single SQL Server engine in a multiprocessing system, SQL Server could not take advantage of multiple CPUs. In a system with multiple CPUs, multiple processes can run concurrently.

Scheduling Tasks to Engines
Figure 2-5 shows tasks queued up for a SQL Server engine. (There are tasks queued up for engines and engines queued up for CPUs.) SQL Server, not the operating system, dynamically schedules client tasks onto available engines from its run queue. When an engine becomes available, it executes any runnable task.
The SQL Server kernel schedules a task onto an engine for processing by a CPU for a configurable length of time called a timeslice. At the end of the timeslice, the engine yields to the CPU and the next process in the queue starts to run. Figure 2-5 also shows the sleep queue with two sleeping tasks. Tasks are put to sleep when they are waiting for resources or the results of a disk I/O operation. The kernel uses the task's stack to keep track of state from one execution cycle to the next.

Multiple Network Engines
Engines are numbered sequentially starting with engine 0. Other than one exception, all engines do the same work. The exception is this: When a user logs into SQL Server, engine 0 handles the login to establish packet size, language, character set, and other login settings. After the login is complete, engine 0 determines which engine is managing the fewest user connections and it passes the file handle for the new client task to that engine, which then becomes the task's network engine.
Communicating Through Shared Memory
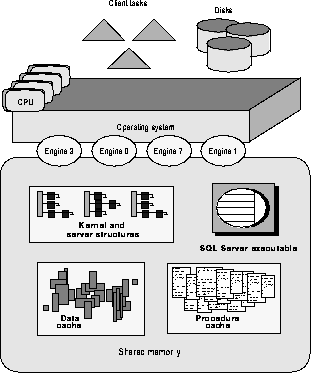
In a multiple CPU configuration, multiple SQL Server engines perform operations that affect data. There must be some way to ensure that the objects don't act completely independently, because if they do, data quickly becomes corrupt. Multiple engines share memory to communicate and use spinlocks to coordinate data access. Figure 2-6 illustrates how all the mutual resources that engines use exist in shared memory, allowing all engines equal access to following resources:
An SMP Processing Scenario
Figure 2-7 shows the SMP subsystems, which consist of clients, disks, the operating system, multiple CPUs, and the SQL Server executable. It also represents the resources in shared memory, which include data caches and procedure cache, queues for network and disk I/O, structures that perform resource management, a sleep queue for processes that are waiting for a resource or that are idle, and the run queue for processes that are ready to begin or continue executing.
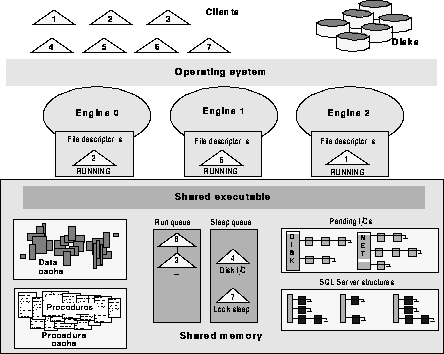
Here's how a SQL Server SMP system manages tasks.
Login and Assigning a Network Manager Engine
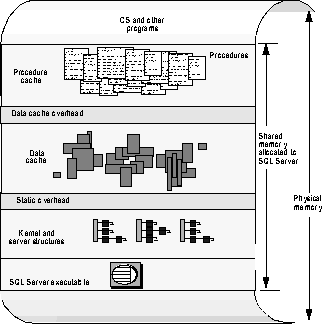
SQL Server Layout in Memory
SQL Server can handle approximately sixteen users with each additional megabyte of memory. This very low user memory requirement means there is more memory for data caching and fewer disk I/Os, which is a performance advantage. When SQL Server starts, it allocates memory for the executable and other static memory needs. What remains after all other memory needs have been met is available for the procedure cache and data cache. Figure 2-8 shows the SQL Server components that take up space in shared memory.