A High Performance DBMS Minimizes Contention
Overview
With Sybase, database performance is a combination of high scalability, large throughput, and fast response time. Sybase defines these factors as follows:
Resource managers are a set of functions that manage global system resources such as pages, buffers, and data structures. The DBMS uses these functions to manipulate different system resources. Resource managers and other specialized tasks rely on the kernel component (see Chapter 4, "A Multiprocessing Kernel") to perform low-level functions. The resource managers handle:
Cache Management
SQL Server 11 data cache management supports an evolving database environment by letting you customize data caches to maintain high performance. Data cache performance also benefits from System 11's "housekeeper" task, which takes advantage of lulls in activity to perform disk writes.
This section describes SQL Server's data and procedure cache technology.
The Data Cache and Named Caches
The data cache contains pages from recently accessed objects such as tables, log pages, and indexes. The Logical Memory Manager (LMM) (also referred to as the Buffer Cache Manager in some documents) lets you "carve up" the global data cache into independent caches that you name. You can then bind database objects or entire databases to your named caches.
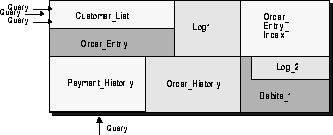
These user-defined caches tailor SQL Server's use of the global data cache to meet the system's current work-load requirements. Figure 3-1 illustrates how you might divide the global cache in a hypothetical production environment. If you have a small, frequently accessed Customer_List table, you might want to devote to it a buffer cache that contains enough buffers to keep the entire table in memory. Because no other table shares that cache, the table's pages remain in memory for quick access. If, on the other hand, you have a large Payment_History table that is only used for low priority batch processing, you can allocate a small cache and assign the Payment_History table to it. Because queries on this table only use buffers from the small cache, only old Payment_History pages are read. These reads do not cause valuable pages (such as those in the frequently accessed Customer_List table) to be removed from cache.
For comparison, Figure 3-2 shows a standard DBMS cache architecture in which all objects occupy a single global cache. Queries must compete with each other for a single buffer manager semaphore.

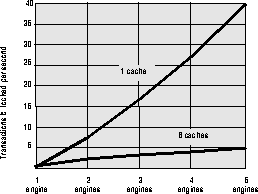
The graph in Figure 3-3 illustrates that using multiple caches reduces contention on the buffer manager semaphore, improving scalability. The logical memory manager allows the system to optimally exploit the available memory resources. This is particularly beneficial in tuning small memory systems; it also helps to get the most out of large memory configurations.
Named Caches and Performance
Adding named data caches can improve performance in the following ways:
Cache Optimization Strategies
System 11 provides commands that give you control over how SQL Server applies optimization strategies to objects, sessions, and queries. Here are some options that support named cache capabilities and provide additional control when tuning queries:
Data Cache Management Summary
No other vendor offers the same level of workload adaptability or sophisticated memory management. Oracle has added "direct reads and writes" so that DSS queries bypass the buffer cache, but there is no way to explicitly manage or configure this capability. Further, direct writes can only be used in special situations where the transaction does not have to be recovered in case of system failure. Oracle also has no ability to perform sequential prefetch operations for large tables or datatypes (there's more on the prefetch capability in Chapter 4, "A Multiprocessing Kernel"). Informix and Microsoft still buffer all memory activity into a single global cache, incurring constant mixed workload conflict and reducing system throughput. SQL Server 11 lets customers configure the RDBMS to meet their mixed workload requirements for high performance at the lowest possible resource cost on all standard SMP systems.
Procedure Cache
The procedure cache is used for query plans, stored procedures, and triggers. SQL Server maintains a most recently used/least recently used (MRU/LRU) chain of stored procedure query plans. As users execute stored procedures, SQL Server looks in the procedure cache for a query plan to use. If a query plan is available, it is placed on the MRU end of the chain and execution begins. If no plan is in memory, or if all copies are in use, the query tree for the procedure is read from a system table. It is then optimized, using the parameters provided to the procedure, and put on the MRU end of the chain, and execution begins. Plans at the LRU end of the page chain that are not in use are aged out of the cache.
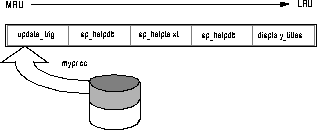
The memory allocated for the procedure cache holds the optimized query plans for all batches, including any triggers. See ``Stored Procedures'' for more detailed information about how the procedure cache works.
Transaction Management and Logging
A DBMS must have a mechanism for keeping track of all transactions. The SQL Server RDBMS does this by keeping a transaction log for each Sybase database. The transaction log records changes that any user makes to that database.
Figure 3-5 shows the data cache during a transaction. The data cache holds the data pages that the transaction is using and all other log pages and data pages that currently reside in the data cache.

Minimizing Log Contention with the User Log Cache
Most relational databases write log records for each update, insert, or delete statement and processes each log entry one at a time. When a log record is written, the logging system must navigate through a synchronization point, the log semaphore, which controls concurrent access to the log by multiple database transactions.
Because the log records for a complete transaction are immediately transferred through the log semaphore, contention on the log semaphore becomes almost nonexistent. Figure 3-6 shows that using the ULC eliminates contention on the append_log semaphore. Contention alleviated by the ULC dramatically increases SQL Server's transaction throughput.

Lock Management
SQL Server locks the tables or databases that are currently used by active transactions to protect them from being modified by other transactions at the same time. Rather than rely on an operating system's lock manager, which can be quite inefficient, SQL Server handles its own locking by means of a memory-resident table. Obtaining a lock takes only a few microseconds and requires no I/O or message traffic.
Page Locks and Table Locks
Table locks generate more lock contention than page locks because no other tasks can access a table while there is an exclusive table lock on it, and if a task requires an exclusive table lock, it must wait until all shared locks are released. Some systems use row-level locking. However, if any change to a row is made that alters the row's space requirements or its location, the lock must be escalated to page level. Other systems escalate to a table-level lock during the actual update. When this happens, all transactions are effectively single-threaded, which is not acceptable in an on-line environment. Many DBMS vendors that use row-level locking "turn it off" during benchmark tests, during which they use page locking to achieve better throughput results.
Lock Promotion
You can use system procedures to configure the number of page locks that SQL Server acquires on a table before it attempts to escalate to a table lock on a server-wide, per-database, and per-table basis. This mechanism is particularly useful for very large databases. A lock promotion threshold lets you set either the number of page locks or a percentage allowed by a statement before the lock is promoted to a table lock.
Spinlock Ratios
SQL Server manages table, page, and address locks using an internal hash table. These tables use one or more spinlocks to serialize access between processes that are running on different engines. For SQL Servers running with multiple SQL Server engines, you can set the ratio of spinlocks protecting each hash table using the table lock spinlock ratio, page lock spinlock ratio, and address lock spinlock ratio configuration parameters.
Deadlocks
A deadlock occurs when two process each hold a lock on a page that the other process needs. Each waits for the other process to release the lock so it can continue processing. You can configure the minimum amount of time that a process must wait before SQL Server checks for deadlocks. If you expect your applications to deadlock infrequently, you can configure long deadlock checking delays and reduce the overhead cost.
Freelocks
A freelock list defines the engine's portion of freelocks from the global freelock pool. The portion is definable through the max engines freelocks configuration parameter as a percentage of the total number of locks. After an engine completes a process, all locks held by that process are released and returned to that engine's freelock list. This reduces the contention for each engine accessing the global freelock list. However, if the number of locks released to the engine exceeds the maximum number of locks allowed in the engine's freelock list, SQL Server moves locks to the global freelock list. This replenishes the number of locks that are available to other engines.
Rows Per Page, Contention, and Concurrency
You can reduce lock contention and improve concurrency for frequently accessed tables by restricting the maximum number of rows stored on a data page, clustered index leaf page, or a nonclustered index leaf page. You can configure the maximum number of rows per page by specifying a value for max_rows_per_page in a create table, create index, or alter table statement.
Page Allocation
The page utilization percent parameter is used during page allocations to control whether SQL Server scans a table's OAM (object allocation map) to find unused pages, or simply allocates a new extent to the table. A low page utilization percent value results in more unused pages. A high page utilization percent value slows page allocations in large tables, as SQL Server performs an OAM scan to locate each unused page before allocating a new extent.
select * from titles at isolation read uncommittedYou can also set isolation level 0 at the session level.