Overview
When Sybase set out to create its first relational database management system, one of the principal design goals was to efficiently use operating system and hardware resources. It was clear that the use of a threaded operating system would be a big step towards realizing the goal.
This chapter describes SQL Server's multithreaded kernel by covering the following topics:
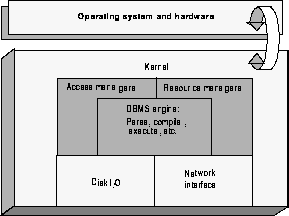
The kernel provides a running environment for the DBMS. As illustrated in Figure 4-1, it creates and manages DBMS tasks, handles disk and network I/O, provides time of day, obtains memory resources from the operating system, and insulates the DBMS, providing operating system and hardware independence.
The operating system services that SQL Server does require are:
The kernel allocates data structures from a pool of shared memory that it obtains from the operating system. Server structures shared between DBMS tasks in a multiprocessor environment require synchronization to avoid overwriting data in the databases they share. The kernel uses spinlocks and semaphores (introduced in Chapter 3) to ensure mutual exclusion between DBMS tasks and engines. When a task requests data, the kernel generates a spinlock, which waits at the data address in memory until the task obtains a lock.
Cost-Based Optimizer
SQL Server uses a cost-based optimizer to determine the best execution plan for a query. It is called a "cost-based" optimizer because it makes intelligent decisions about the fastest way to perform a query based on the time cost. A syntax-based optimizer, on the other hand, has no knowledge of the actual data or size of the tables¯and SQL Server's optimizer looks at both.
Optimizer Use of Cache
Sybase's fully integrated query optimizer evaluates the type of data being accessed and selects the best I/O size for each object. It uses the buffer sizes available in the named cache to which that object is bound, automatically optimizing I/O for each application.
The optimizer also determines when a query will access a large number of sequential pages in a table and dictates the use of sequential prefetch in these cases. The ability to choose optimal I/O size combined with asynchronous prefetches of large amounts of data gives quick results for decision-support applications, while preserving the high performance and throughput of OLTP applications running on the same system. For the first time in an open RDBMS, a single instance of the database can support mixed workloads without compromise. Also see ``Tunable Block I/O''.
Stored Procedures and Triggers
Stored procedures and triggers are optimized when the stored procedure or trigger object is first executed and the query plan is stored in the procedure cache. If other users execute the same procedure while the plan resides in the procedure cache, they'll receive a performance benefit because the compiled query plan is already in cache and need not be recompiled.
Updates
SQL Server 11 implements complex query optimization that minimizes the number of logical I/Os and streamlines update operations. The optimizer handles updates in different ways depending on the changes being made to the data and the indexes used to locate the rows.
Direct Updates
SQL Server performs direct updates in three ways: in-place updates, cheap direct updates, and expensive direct updates.
In-Place Updates
SQL Server performs in-place updates whenever possible. In an in-place update, subsequent rows on the page do not move; the row IDs remain the same and the pointers in the row offset table do not change. Figure 4-2 shows an in-place update. The pubdate column is fixed length, so the length of the data row does not change. The access method in this example could be a table scan or a clustered or nonclustered index on title_id.

Cheap Direct Updates
If SQL Server cannot perform the update in place, it tries to perform a cheap direct update¯changing the row and rewriting it at the same offset on the page. Subsequent rows on the page move up or down so that the data remains contiguous on the page, but the row IDs remain the same. The pointers in the row offset table change to reflect the new locations.
Expensive Direct Updates
If the data does not fit on the same page, SQL Server performs an expensive direct update, if possible. An expensive direct update deletes the data row, including all index entries, and then inserts the modified row and index entries. SQL Server uses a table scan or index to find the row in its original location and then deletes the row. If the table has a clustered index, SQL Server uses the index to determine the new location for the row; otherwise, SQL Server inserts the new row at the end of the heap.
Deferred Updates
SQL Server uses deferred updates when it cannot make a direct update. Deferred updates are the slowest type of update; they incur more overhead than direct updates because they require re-reading the transaction log to make the final changes to the data and indexes. This process involves additional traversal of the index trees. For example, if there is a clustered index on title, this query performs a deferred update:
update titles set title = "Portable C Software" where title = "Designing Portable Software"

Tunable Block I/O
There is virtually the same amount of overhead associated with all data packets no matter what size they are. Most of the time that an I/O operation consumes is spent queueing I/O requests, seeking on disk, and physical positioning. When more data can be sent in fewer packets, it reduces overhead and improves throughput. Large I/O can greatly improve performance for some types of queries, such as those that scan entire tables or ranges of tables.
Large I/O for Data Caches
SQL Server 11 can perform I/O requests in various block sizes ranging from 2K to 16K for data and log pages. Each object in the database can be retrieved using different block sizes. It may, for example, be best to fetch text/image data using an 8K block size and data records using a 4K block size. SQL Server's ability to use different block sizes allows it to make very efficient use of memory. Several pages can be fetched in a single I/O, reducing the overall number of physical I/Os and increasing performance.
Large I/O can increase performance for:
Configurable I/O for the Log
The transaction log file can also be bound to its own cache and configured for the most appropriate I/O block size. Using large I/Os for the log in addition to the user log cache can significantly boost OLTP and data warehouse performance. See ``Minimizing Log Contention with the User Log Cache''.
Shared Buffers
Shared data buffers and shared procedure buffers are other SQL Server architectural features that can reduce the number of I/O operations. If one task's request brings data into cache, the next task that needs that data gets a performance benefit because it doesn't have to wait for disk access¯the data is used from cache (if the data is still there). Similarly, if a user calls a procedure into cache, and the same or another user calls the procedure while it is still in cache, the caller gets a performance benefit.
Keeping Data in Cache
SQL Server writes pages to disk only when the SQL Server has spare cycles (through the housekeeper task), when buffer space is needed for new records, or when you issue a checkpoint command to write all modified pages in memory to disk. Some other database architectures require that a data page be written immediately to disk after a record is altered in order to guarantee data consistency. SQL Server's write-ahead logging and shared transaction log strategies allow it to keep frequently accessed pages in cache for performance gains and guarantee data consistency at the same time.
Network Features
SQL Server's network architecture is based on the ISO OSI Reference Model for the network protocol stack. SQL Server supports most common network protocols, and you can install additional protocols if necessary. Application software interacts directly with the APIs, so application developers need not get bogged down by the intricacies of network-level protocols.
Multiple Engines Handle Network Connections
``Multiple Network Engines'' introduced System 11's capability for handling more than 10,000 connections using multiple network engines. When a client logs in, SQL Server assigns the client's I/O tasks to the engine that is currently handling the smallest number of network connections. That engine handles all of the client's network operations until the client connection terminates.
Using network affinity migration offers the following benefits: